
Chris Potts: AI language models have large gaps to address, even as they move toward true understanding
The professor of linguistics and expert in large language models discusses their fast-growing capabilities in understanding, their major limitations and gaps, and where he focuses his effort


Chris Potts is one of the foremost experts in natural language processing and understanding. He is a Professor and Chair of the Stanford Linguistics Department. He is also Professor, by courtesy, in Computer Science. He is a member of the Stanford Natural Language Processing (NLP) research group and Stanford AI Lab (SAIL), and the host of the Natural Language Understanding Podcast.
Over the last few years of relentless advances in artificial intelligence (AI), Luohan’s community of social scientists has largely aligned around recognizing AI as a powerful general-purpose technology that may deliver broad productivity gains which have eluded many economies recently. Given this consensus, it is critical to understand the state of this technology. What are the capabilities of these models? Are they are getting closer to demonstrating true understanding of language and concepts? Where are there gaps and how are AI researchers addressing them?
For insights on these questions, we spoke with Professor Chris Potts, a leading scholar of natural language processing at Stanford. In February 2023, Potts gave an incredibly information-rich Stanford webinar titled “GPT-3 and Beyond.”1 At a time when social media was universally in awe of OpenAI’s ChatGPT, Potts not only gave a comprehensive review of the innovations behind the latest large language models (LLMs), but also laid out the immense gaps to be resolved in the technology. The rapid and real world deployment of these language models gives even more impetus to address those gaps.
Although ChatGPT has been the development that captured the world’s attention, for Potts it has been several years of big developments. Particularly noteworthy was the release of OpenAI’s GPT-3 in 2020 which causes rethinking methods in Potts’ research community.
Language models of sizes 1000 times larger than just a few years ago are now the norm. And they are reaching a threshold where they show ‘emergent properties’ not before present in smaller models, such as the ability to answer advanced math questions or unscramble word puzzles.
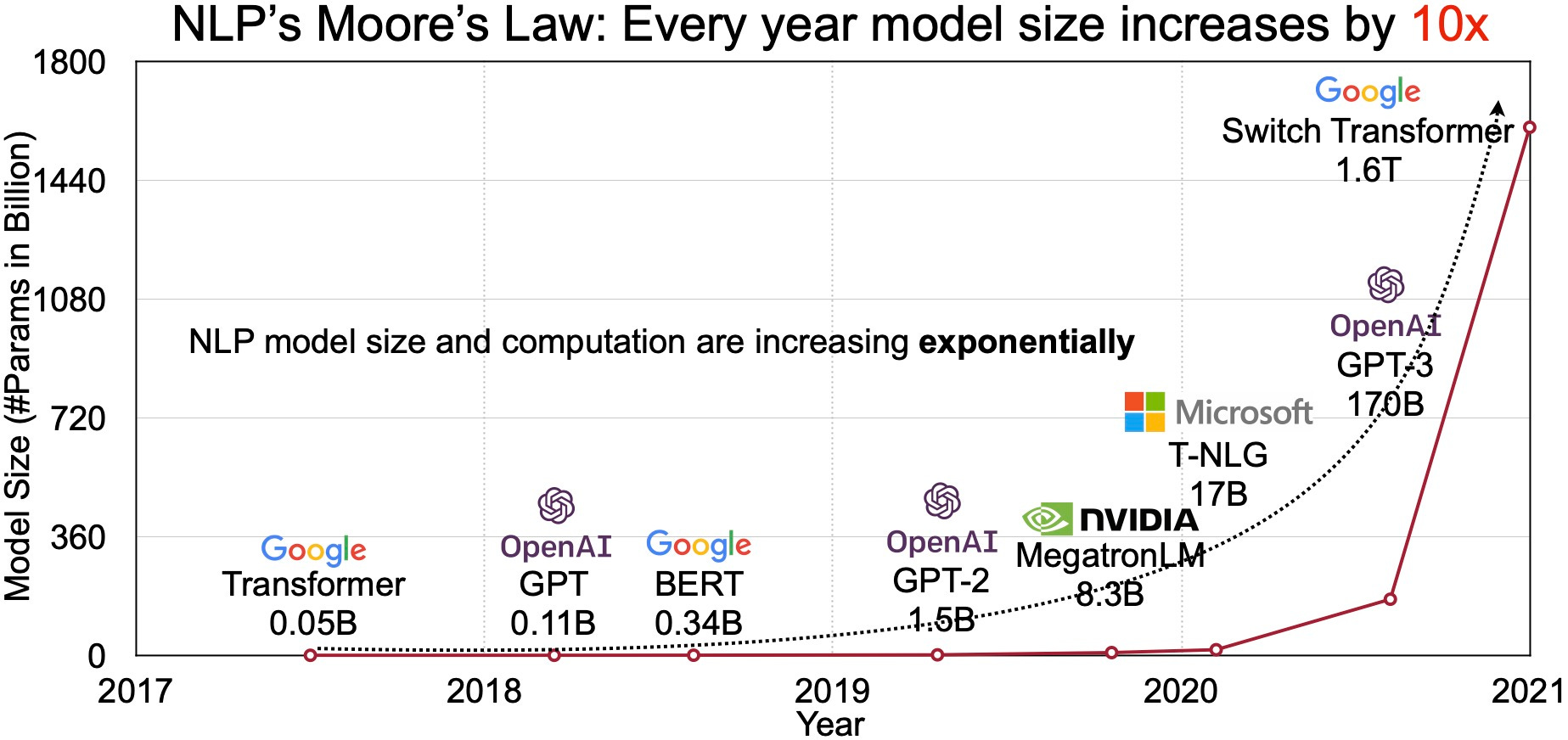
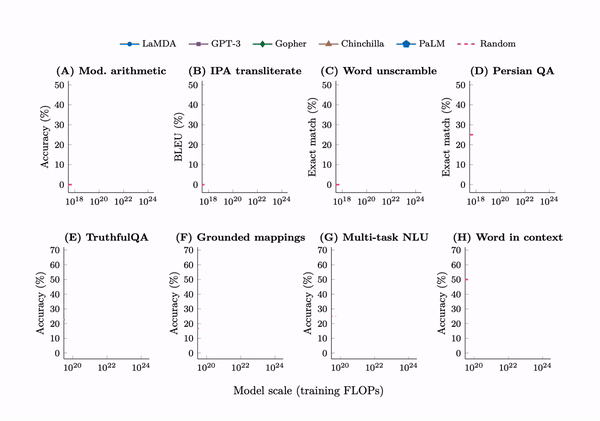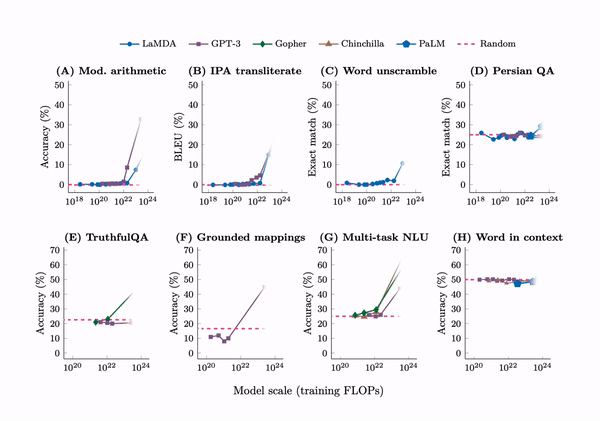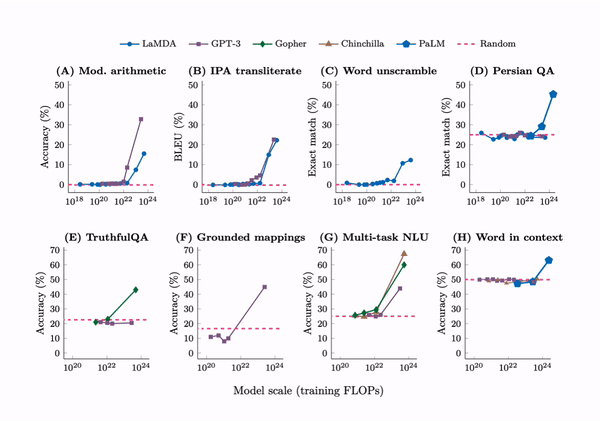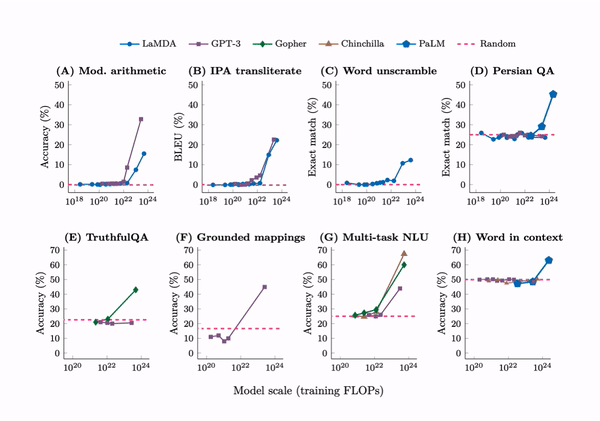
Transforming machine learning architecture and human input
It’s instructive to review what got us here in a remarkably short period of time. It was only five years ago in 2017 when a Google team introduced the first foundational piece - the Transformer architecture, showing drastically better performance for tasks like speech recognition and natural language processing. Transformer relied on an ‘attention’ mechanism that relate words and tokens to other parts of a text, giving models much better understanding of contextual meaning.2 This was a major milestone — for evidence of this we can be reminded the acronym GPT stands for Generative Pre-trained Transformer.

The second key innovation was the use of self-supervised learning (SSL) methods. In classic supervised learning, data labeled by humans attempt to train model on particular relationships. In contrast, SSL allows training on unstructured data. Because less human effort is needed, SSL allows for very large-scale pre-training. Early on, it was not known how well SSL would work, and Potts remains amazed that unstructured training has worked so well. Feeding a lot of quantity brought about a quality of its own.
“It's very clear that our best models by and large right now are also trained with what's called reinforcement learning with human feedback, where humans directly express preferences about what good outputs are given some inputs and express preferences about how to rank different outputs. And that takes us way beyond self-supervision, and into the classic mode of AI where most of the intelligence is in the end being expressed by humans.”
Given self-supervised learning, are humans no longer important to success? Potts thinks the exact opposite, and he asserts that the final big innovation was a human input mechanism. This was reinforcement learning from human feedback (RLHF). For example, a human reviewer might give a binary good or bad rating to outputs from the model, or rank outputs. This information is then fed back into the model to improve it. Even small amounts of human input seem to be extremely powerful. OpenAI used RLHF for its InstructGPT model in January 2022, and later for ChatGPT. Potts says that OpenAI’s employment of large teams to conduct RLHF gave its models the edge in producing human-like responses.
Indeed, while computing power, model size, and other technical factors explain some of today’s success, perhaps the biggest revolution has been the change in these method advances that changed the form factor of human input. We can now build models on voluminous data without need for laborious human labeling. And then we can use intuitive forms of human feedback and prompting to fine-tune models, instead of deep learning programming. This paradigm shift has led to today’s impressive capabilities and may offer clues for how humans will create and interact with technology in the future.
Potts: Models seem to be moving to true understanding
“I think we are seeing a lot of evidence that these models are inducing a mapping from linguistic forms to concepts as we recognize them as humans. And that does suggest to me that they are on the road to true understanding. That's going to make their behavior increasingly systematic. It does not imply that their behavior will be more trustworthy anymore than that people are going to be invariably trustworthy just because they have semantics.”
Given the rapid improvements in AI models, are we closer to them having true understanding? This has been the source of heated debate. In October 2020, Potts himself mused in a blog post on this question: Is it possible for language models to achieve language understanding? While noting that models are just statistically processing symbols in training data, Potts nonetheless posited that “we have no reason to think that language models cannot” achieve understanding.
Fast forward two and a half years, and Potts’ views seem more plausible to the casual observer with ChatGPT’s performance, and to him as well. Potts believes that models are indeed “inducing a mapping from linguistics forms to concepts.” He points out that one reason for the leap is that models are not just trained on direct text, but also on meta-data including contextual and sensory information. These help form a much broader understanding of relationships in the world. All this suggests to Potts that language models “are on the road to true understanding.”
In contrast to Potts’ view that models are on the path to ‘understanding,’ Noam Chomsky, Ian Roberts, and Jeffrey Watmumull wrote a widely circulated op-ed in the New York Times (“The False Promise of ChatGPT”) which downplayed the ability of models to achieve understanding from statistically processing data alone.3 I asked Potts about this article. As someone who often acknowledges flaws in the technology, he disagreed with the article's implied premise that “just because humans learn in one way, these other these models to achieve the same end state as humans need to learn in the same way.” Potts says that language models can learn in different ways, and says “nobody has shown me that the end state couldn't be the same qualitatively.”
He is particularly puzzled by one of the article’s views that these models cannot explain semantics: “The correct explanations of language are complicated and cannot be learned just by marinating in big data.” But according to Potts, the past three years has shown that AI has indeed gained semantic understanding from training on data. Going one step further and mapping from forms to meanings is more difficult. But even here Potts is cautiously optimistic about machines: “I have some conviction, based on experiments we’ve done, that we’re on our way.”
Minding the gaps to truly unleashing AI’s potential
So where are the gaps we must close? In Potts’ February presentation at Stanford Online, he laid out four major areas that he sees as veins of necessary work and research. All four areas aim at making our LLMs more useful and less problematic:
Retrieval augmented in-context learning
Better benchmarks
“Last mile” for useful applications
Explainability
Focus 1: Retrieval augmented in-context learning
“A major challenge for the field is, is getting control of these models so that we could plausibly say that we have a knowledge store, or index of the web, or whatever else… and we're able to prevent the language model from going outside of its knowledge store. It should produce answers that synthesize actual information.”
Models such as GPT-4 are one-size-fit-all behemoths pretrained on heaps of data. Although this makes for an impressive chatbot, a large frozen model may not be best for tasks that require more accurate, timely, and specific information.
Retrieval augmented in-context learning is a solution that promises to address this. This is a method that aims to combine targeted retrieval of data with a large model’s semantic abilities. Without being able to retrieve specific data, our large models are answering inputs based on an entire corpus of general knowledge. This produces results that are not grounded in reality, inaccurate, and inconsistent. They are not even rooted in basic web information, they do not provide good tracing for the source of information, and they synthesize information in a haphazard fashion. As result, they often hallucinate links or papers that do not exist.
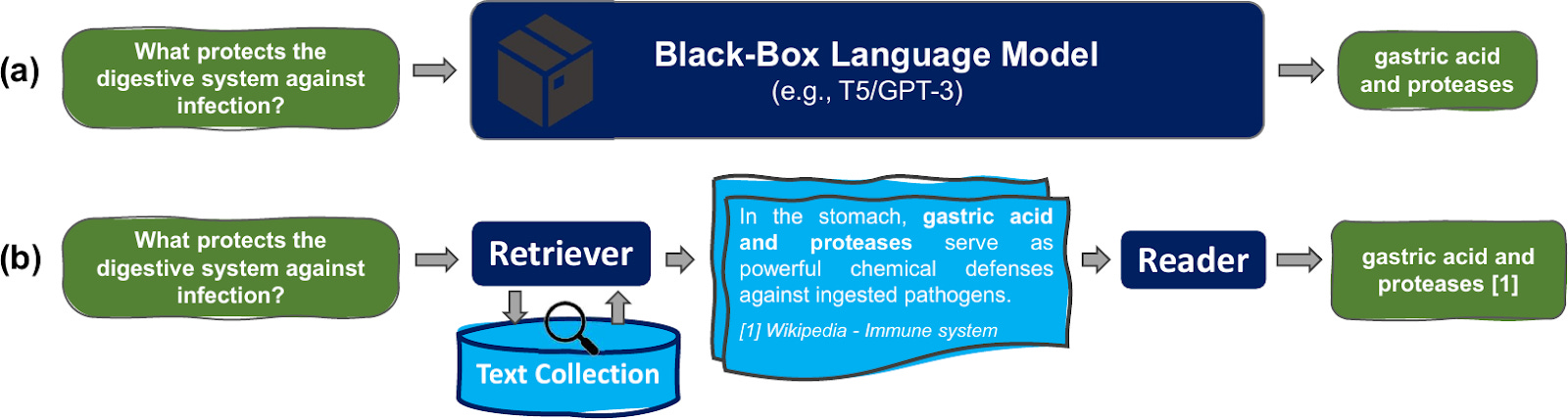
Beyond output quality issues, these general models are inefficient. We should not be asking a general LLM to do math problems without linking it to a simpler calculator function. They cannot be easily updated to incorporate small but crucial new information.
For Potts, all of this means research should focus on this critical gap: “retrieval augmentation is the step zero.”
Focus 2: Better benchmarks
Economists certainly understand the importance of accurate measurements. At Luohan, our first big symposium was indeed the topic “Measuring the New Economy.” Many economists have felt we are not accurately measuring an increasingly digital and intangible economy and this is distorting much of our policies.
Similarly, Potts sees major problems in how we currently measure and report the capabilities and successes of AI models. There’s been quite a lot of ‘positive results bias’: we are inundated with stories of amazing successes. But how many failure cases are there? And even more importantly, are these tools doing what they aim to do? How should we try to define what they do? Pott’s Ph.D. student Omar Khattab sums up the problem succinctly that exploration is easy, but figuring out how successful the models are is currently hard.
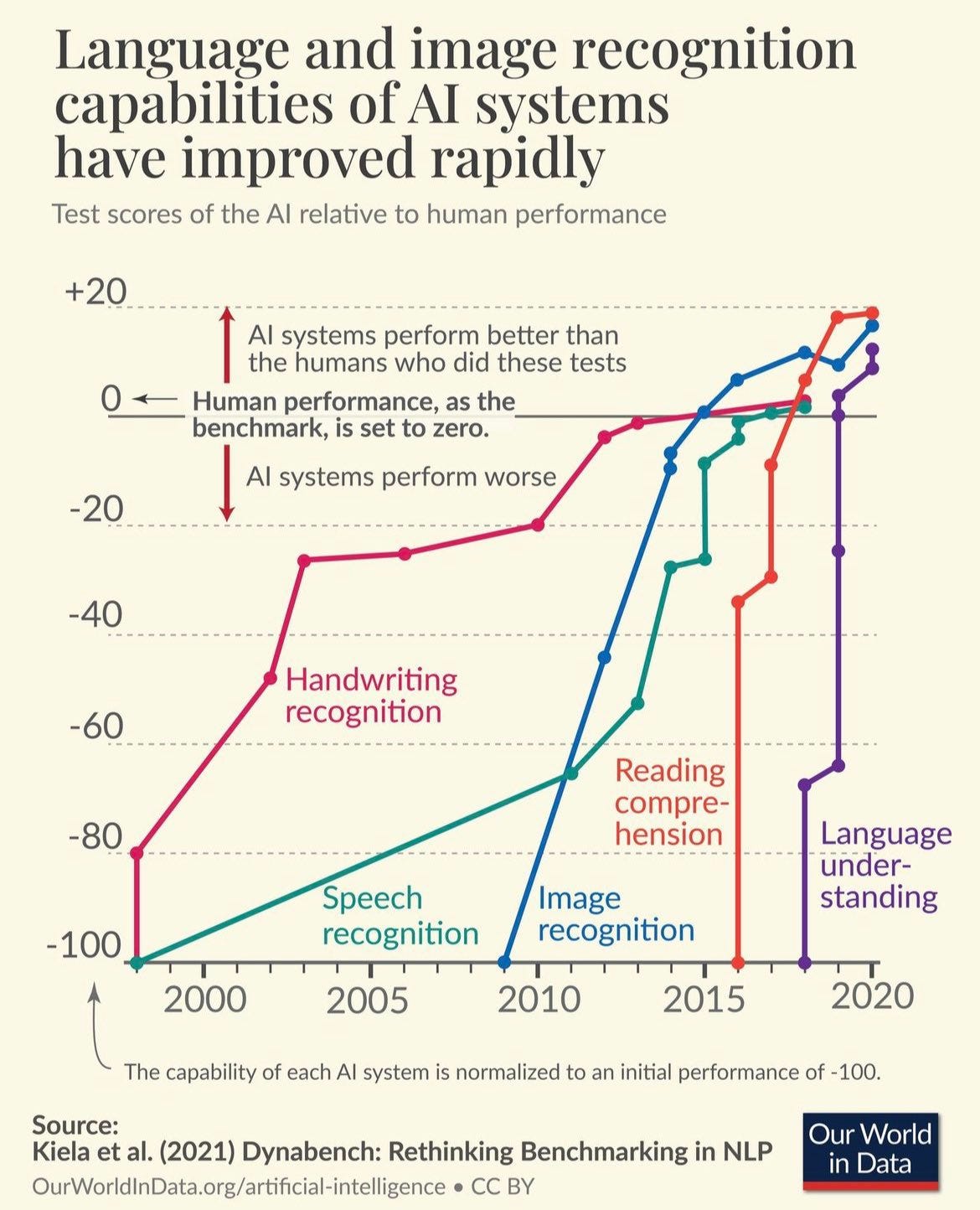
Historically, we have established benchmarks for tasks such as character recognition, speech-to-text, image identification, and others. Usually, a line for human performance is determined. Some of the early benchmarks such as MNIST for digits recognition and Switchboard for speech-to-text took around twenty years for machines to surpass the human line, a point known as "saturation." But the recent mushrooming abilities of AI models have seen them saturate benchmarks rapidly.4 In natural language, the benchmark General Language Understanding Evaluation (GLUE) was saturated in less than a year, a fate shared by its successor SuperGLUE.
Deciding what to measure is complex. In language, interpretation is one area that is intentionally ambiguous for humans. People as individuals naturally “vary in their interpretation of language.” So trying to assign a ‘correct’ label, and then marking down humans who deviate misses the point. A better measurement would take into account discussion, debate, and variations.
For Potts, a big paradigm shift will be to move away from simply tagging to human performance to quantify how well humans do what may be a machine-advantaged task. This causes measures to be “systematically misleading,” says Potts, but he is optimistic that we can move “into an era in which we can do evaluations that are much more meaningful and much more at the level of whether we're, for example, helping a user with a task they want to perform.”
Focus 3: Explainable AI
“No amount of behavioral testing could give you a guarantee about what was going to happen on new inputs. The best hope we have is to deeply understand how these models work internally. That's the project of explainability. It's not a panacea. But it is the thing that would give us something more like a guarantee and also help us diagnose problems.”
A major shortcoming in many models is that they cannot give clear explanations for how they arrive at their outputs. This is a gap for many businesses, to whom black boxes make for bad products. Among many issues, ethical and quality concerns are paramount. There are many applications where the lack of explainability will restrict or limit use.
For Potts, the key is to get to the point where we are reasonably certain these systems will produce reasonable outputs for given inputs. The models are often tested with a set of behavioral tests. But in the real world, what “the system encounters is much wider and more varied and more surprising” and in turn, the model “does surprising and sometimes shocking and awful things.”
The good news, according to Potts, is that the technical issues are likely surmountable as LLMs are “closed deterministic systems that we can study to our heart's content.” The bigger challenge may lie in defining the human aspects of explanation. Once we start to look under the hood, we may have a slew of other questions. What if we find biases or errors? Who decides what is biased, or what is trustworthy? What systems are needed to check on and decide how to deal with these issues?
Focus 4: Climbing the last mile
“If you're just an AI practitioner, and you think I've got this powerful model, I'd like to change the world with it. Very often you're stuck at that point. Because what you needed is to begin with an actual problem that needed to be solved, then find a way that AI would help solve it.”
Potts compares the frequent claims of AI reaching big milestones as analogous to the climber who has reached the Everest base camp and claims they’ve conquered Everest. The last 5% is often the toughest slog, and Potts thinks this will probably be the case with many AI applications. For the ‘last mile’ problem, “you're talking about people, domains, interfaces, and all of that other stuff that really embraces much more of humanistic aspects of this product design and being grounded in whatever domain you're trying to have an impact in.”
The purpose-filled road ahead
The current zeitgeist suggest we will see rapid deployment of these generative AI technologies. Not a week goes by without major announcements from major firms. Still, economists know from history that it can take time for general-purpose technologies to reach their full potential across society.
That makes work on Potts’ four areas critical. If he and the AI community see success in their efforts, it will help AI language models be more usable, and see wider deployment to solve more real problems.
This does not mean AI will solve many of societies’ problems. AI itself will bring social externalities, both positive and negative, and Potts personally cannot rule out the potential for some calamities. Many problems are simply beyond the scope of the AI technology alone. But getting a grasp of the technology certainly is the first step to engendering trust that we know what these systems are doing, that we can accurately measure their success, and that we can ultimately use them to serve our social ends.
Potts, Chris. Is it possible for language models to achieve language understanding? (October 6, 2020) Retrieved from https://chrisgpotts.medium.com/is-it-possible-for-language-models-to-achieve-language-understanding-81df45082ee2
A. Vaswani et al., Attention is all you need. Adv. Neural Inf. Process. Syst., 30, 5999–6009 (2017). http://arxiv.org/abs/1706.03762
Noam Chomsky et al., 2023/3/8. The False Promise of ChatGPT. New York Times https://www.nytimes.com/2023/03/08/opinion/noam-chomsky-chatgpt-ai.html
Douwe Kiela, Max Bartolo, Yixin Nie, Divyansh Kaushik, Atticus Geiger, Zhengxuan Wu, Bertie Vidgen, Grusha Prasad, Amanpreet Singh, Pratik Ringshia, Zhiyi Ma, Tristan Thrush, Sebastian Riedel, Zeerak Waseem, Pontus Stenetorp, Robin Jia, Mohit Bansal, Christopher Potts, and Adina Williams. 2021. Dynabench: Rethinking Benchmarking in NLP. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 4110–4124, Online. Association for Computational Linguistics.
 | A guest post by
|